Text Inspector
The Text Inspector tool helps you quickly analyze any piece of text. It provides detailed statistics such as word count, character count, line count, estimated reading time, and more, all in a clean and easy-to-read interface. You can type or paste text directly, or open text files from your system for analysis.

Counters and Statistics
Section titled “Counters and Statistics”The Text Inspector provides a rich set of counters and metrics to help you understand your text better. Each counter updates instantly as you type, paste text, or drop a file into the field.
Text Counters
Section titled “Text Counters”- Words: Counts the total number of words in the text.
- Characters: Displays the total number of characters, including spaces.
- Sentences: Estimates the number of sentences based on punctuation marks and structure.
- Lines: Shows how many lines your text contains.
- Paragraphs: Counts paragraphs by detecting blank lines between text blocks.
Time Estimates
Section titled “Time Estimates”- Reading Time: Approximates how long it would take to read the text at an average reading speed.
- Speaking Time: Estimates how long it would take to speak the text aloud at a natural pace.
Encoding Information
Section titled “Encoding Information”- ASCII Size: Shows the file size if the text were encoded as ASCII.
- ASCII Only: Indicates whether the text contains only ASCII characters.
- UTF-8 Size: Displays the text size when encoded in UTF-8.
- UTF-16 Size: Displays the text size when encoded in UTF-16.
- Line Endings: Detects the type of line endings used (LF, CRLF, or CR).
- BOM: Shows whether a BOM is present in the file. This check only works when a file is dropped into the input field.
Token Counting
Section titled “Token Counting”The Text Inspector can count tokens for a range of models, which is useful when working with LLM APIs that bill by the token or enforce context window limits. Token counts update automatically as you edit text.
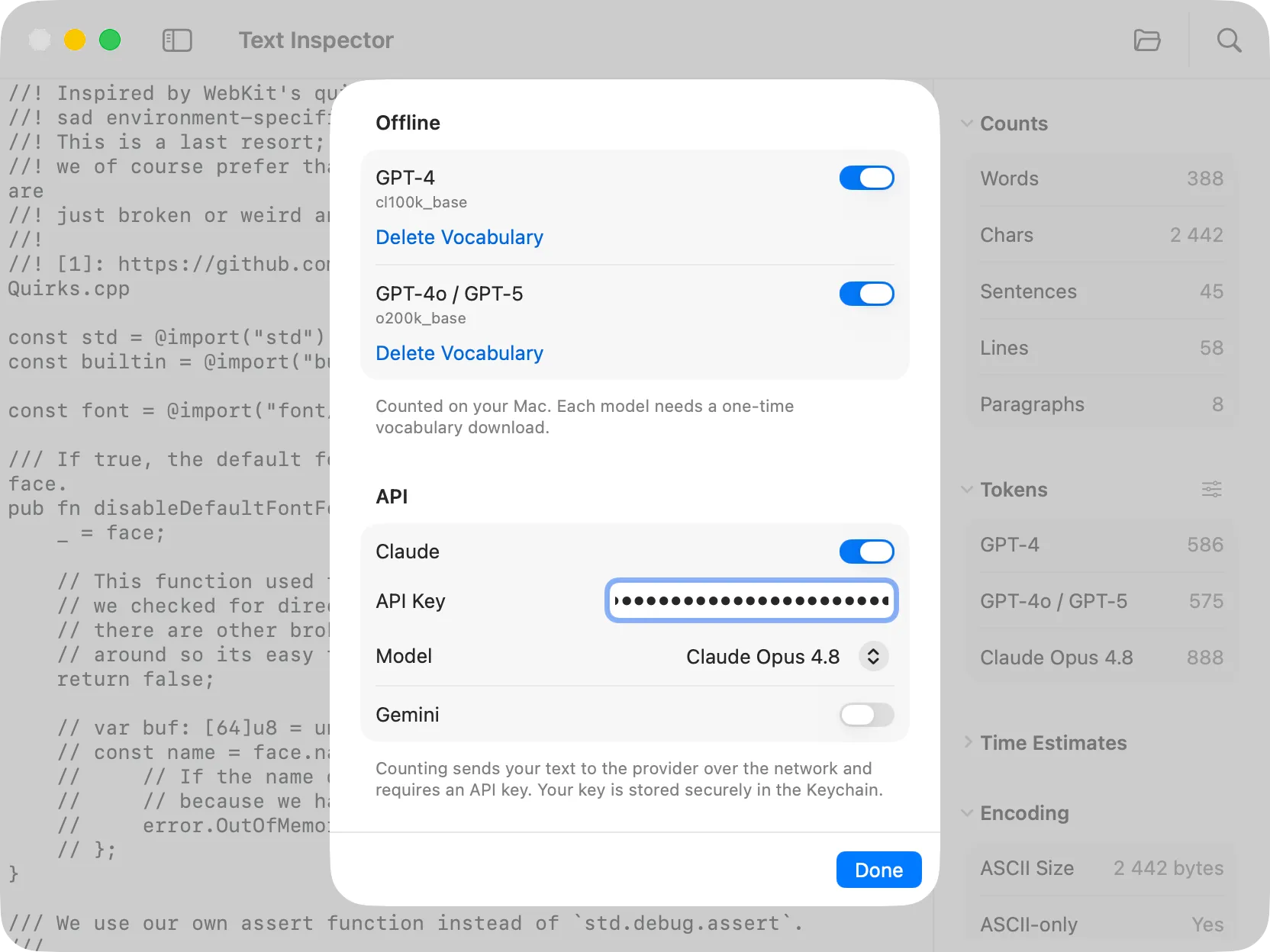
Offline Models
Section titled “Offline Models”Offline token counting runs entirely on your Mac using OpenAI’s tiktoken vocabulary files. No text is sent anywhere. The following encodings are supported:
- GPT-4 (
cl100k_base) — used by GPT-4 and GPT-4 Turbo - GPT-4o / GPT-5 (
o200k_base) — used by GPT-4o and GPT-5
Each encoding requires a one-time vocabulary download (~1.7 MB for GPT-4, ~4 MB for GPT-4o / GPT-5). You can manage downloads in the token settings panel.
API Models
Section titled “API Models”Token counting for Claude and Gemini is done via the provider’s API, which means the text is sent over the network. An API key is required for each provider and is stored securely in the Keychain.
- Claude — counts tokens using the Anthropic API against your chosen model
- Gemini — counts tokens using the Google API against your chosen model
API counts are not updated automatically — click Count in the Tokens section to trigger a count on demand.
Configuring Tokenizers
Section titled “Configuring Tokenizers”Click the sliders icon in the Tokens section header to open the token settings panel. From there you can enable or disable individual models, download vocabulary files for offline encodings, and add API keys for Claude and Gemini.